2022. 2. 1. 22:29ㆍ보안 연구/Reversing
본 티스토리 블로그는 PC 환경에 최적화되어 있습니다.
모바일 유저분들은 아래 네이버 블로그를 이용해 주세요.
바이너리 언패킹(2) - 압축과 엔트로피
본 네이버 블로그는 모바일 환경에 최적화되어 있습니다. PC 유저분들은 아래 티스토리 블로그를 이용해 ...
blog.naver.com
안녕하세요! ICMP입니다!
저번 시간에는 엔트로피의 계산 과정과 이를 파이썬으로 구현했으며, 오늘은 압축과 엔트로피의 관계를 확인해 보고 동적 언패킹으로 OEP를 찾는 코드를 작성해 보도록 하겠습니다.
1. 압축과 엔트로피의 관계
정보를 표기하기 위한 최소한의 비트 수가 엔트로피인데, 그럼 파일을 압축하면 크기가 줄어들므로 엔트로피가 줄어들까요?
결론부터 말씀해 드리자면 압축 방식에 따라서 다르지만 엔트로피는 대체적으로 증가합니다.
왜냐하면, 정보라는 것은 압축할 수 없으며 정보를 표기하는 매체인 코드(ascii, ebcdic ... 등 우리가 일반적으로 data라고 언급하는 녀석들)는 압축할 경우 더 많은 H, 즉 높은 엔트로피를 가집니다.(여기서 중요한 것은 엔트로피와 정보는 같지 않다는 것입니다.)
즉, 데이터를 압축하게 될 경우 파일의 사이즈는 작아지더라도 한 character가 가지는 엔트로피 값은 증가합니다.
정확한 내용은 아래 링크를 참고하시길 바랍니다.
Does the compression of information reduce entropy?
Answer (1 of 3): Data compressionincreases Shannon entropy(symbol H), the average expected information value carried by the data, measured in units of shannon(Sh, a.k.a. bits (binary digits, 1 and 0)). “Information” can not be compressed, only the code
www.quora.com
실행 전 언패킹이 되지 않은 악성코드와 실행 압축이 풀린 악성코드의 엔트로피는 반드시 그 차이가 나타날 수밖에 없습니다.
아래는 gcc로 컴파일 한 파일과 upx 패킹을 건 후 immunity 디버거로 각각 열어본 화면입니다.
#include <stdio.h>
int main(){
printf("hello world");
return 0;
}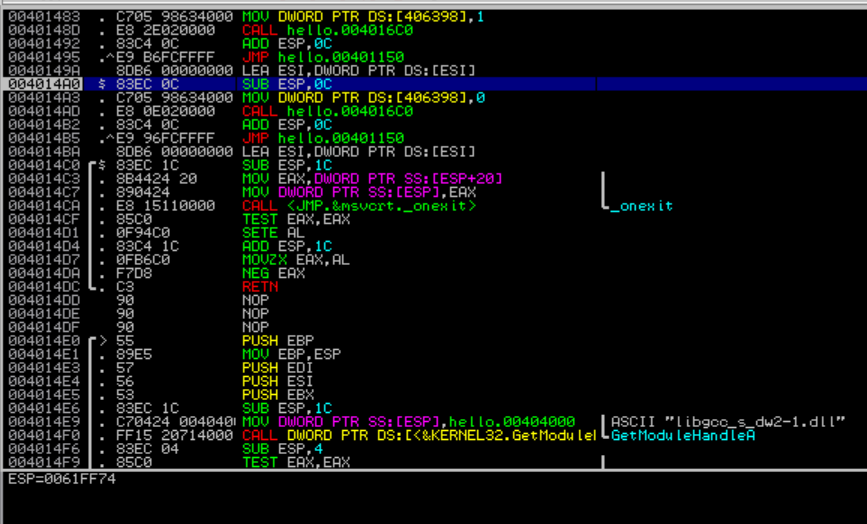
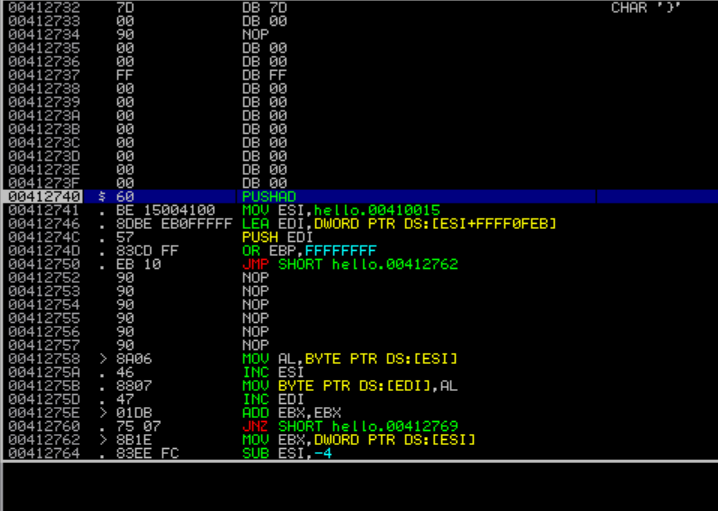
패킹을 거니 내부 어셈블리 코드 일부가 압축되고 oep도 바뀐 것이 확인되었습니다.
저번에 작성해놓은 엔트로피 측정 코드를 이용해 바이너리의 엔트로피를 확인해 본 결과 다음과 같이 값이 패킹을 건 파일이 커진 것을 확인할 수 있습니다.
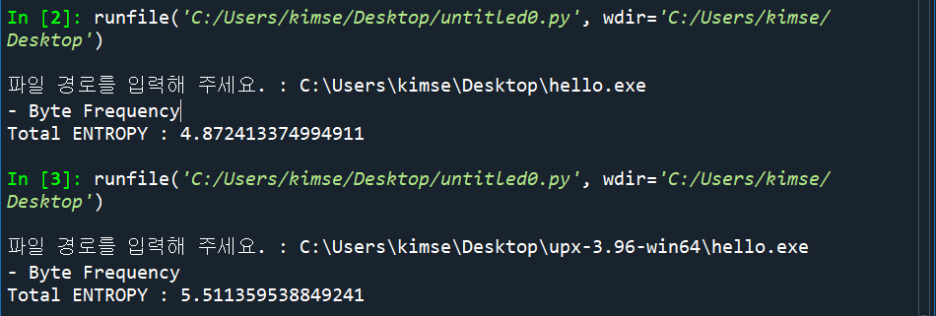
2. 엔트로피 측정과 언패킹 자동화
이제 우리가 해야 할 부분은 OP 코드 단위로 실행될 때 메모리 단의 엔트로피 값을 구해야 합니다.
직접적인 디버거를 구축하기는 어렵기에 immunity의 파이썬 스크립트 기능을 활용하도록 하겠습니다.
아래는 immunity, ollydebugger의 스크립트 기능에 대해 아주 잘 설명해놓은 사이트이니 참고 바랍니다.
Starting to write Immunity Debugger PyCommands : my cheatsheet | Corelan Cybersecurity Research
When I started Win32 exploit development many years ago, my preferred debugger at the time was WinDbg (and some Olly). While Windbg is a great and fast debugger, I quickly figured out that some additional/external tools were required to improve my exploit
www.corelan.be
Assemble, Disassemble, Search
Assebmble, Disassemble, Search 어셈, 디스어셈, 서치에 대해서 알아보도록 하겠습니다. ImmunityDBG에서 어셈블리어를 Hex 값으로 Hex값을 어셈블리어로 변환하고, 해당 Hex 값이 어디에 위치해 있는지 찾아
kblab.tistory.com
엔트로피를 통해 궁극적으로 언패킹이 완료되는 시점의 jmp를 찾아내는 코드를 작성해 보도록 하겠습니다.
기본적인 동작은 아래와 같습니다.
(정확한 순서도 규칙에 맞춰서 작성한 것은 아니기에 참고용으로만 보시길 바랍니다.)
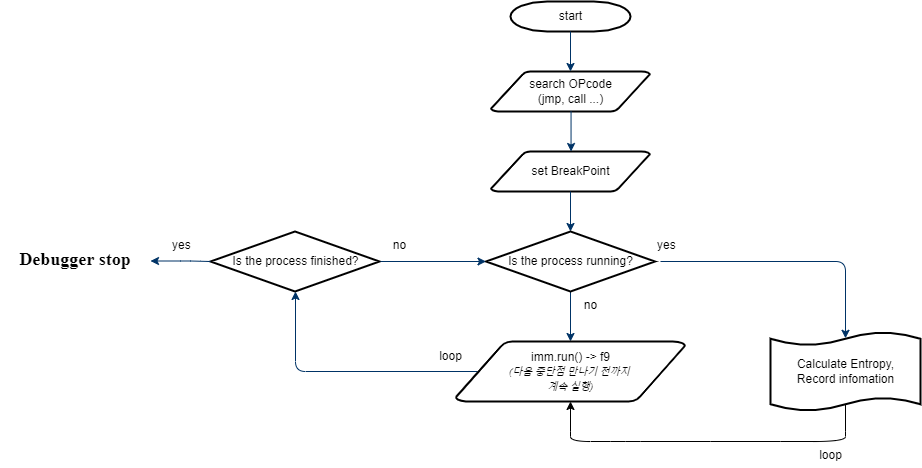
1. 메모리에 올라온 바이너리 OP 코드 중 "jmp", "call" 부분을 모두 중단점을 건다.
-> 모든 OP 코드에 중단점을 걸어 엔트로피를 측정하면 좋지만, 장비에 상당히 무리 가는 작업입니다.
-> 값을 복사하더라도 실행 분기를 바꾸기 위한 어셈블리 코드는 jmp, jne, call, ... 등이 존재합니다.
-> 현재는 단순한 테스트 목적이므로 jmp, call 어셈블리 코드에만 중단점을 걸도록 하겠습니다.
(op 코드에 대한 정보는 아래 링크를 참고해 주세요.)
CALL — Call Procedure
#SS(selector) If pushing the old values of SS selector, stack pointer, EFLAGS, CS selector, offset, or error code onto the stack violates the canonical boundary when a stack switch occurs.
www.felixcloutier.com
2. 프로그램을 실행시킨다.
3. 중단점을 만나면 엔트로피를 측정한 후 다음 중단점을 만나기 전까지 계속 실행시킨다.
아래는 해당 로직에 맞춰서 작성된 코드입니다.
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 31 16:17:41 2022
@author: kimse
"""
#findinstruction.py
#-*- coding: utf-8 -*-
from immlib import *
import math
def main(args):
imm = Debugger()
start = 0x401000
end = 0x412fff
count = 0
#break_point_Addr = []
#break_point_Addr += Set_breakPoint_Targets(imm, start, end)
imm.run()
while(True):
if(not(imm.isRunning())):
f_stream = read_Binary(imm, start, end)
result_entropy = cal_Entropy(imm,
f_stream,
end-start)
record_Entropy(imm.getRegs()['EIP'],
result_entropy,
count)
count += 1
if(imm.isFinished()):
imm.quitDebugger()
imm.run()
def Set_breakPoint_Targets(imm, start, end):
jmp_list = imm.search('\xea') # 바이트 코드로 jmp인 주소를 모두 검색한다.
jmp_list += imm.search('\xeb')
jmp_list += imm.search('\xe9')
jmp_list += imm.search('\xff')
call_list = imm.search('\xe8') # 바이트 코드로 call 인 주소를 모두 검색한다.
call_list += imm.search('\x9a')
BP_list =[] #중단점 설정할 주소를 리스트에 저장한다.
for i in jmp_list:
if(i>=start and i<=end):
BP_list.append(i)
for i in call_list:
if(i>=start and i<=end):
BP_list.append(i)
for i in BP_list: #log 창에 중단점 정보를 표시한다.
imm.log("- set BreakPoint at -->"+hex(i))
imm.setBreakpoint(i)
return BP_list
def read_Binary(imm, start, end):
imm.log("read binary & wait a minutes...")
file_byte_stream = imm.readMemory(start, end-start)
return file_byte_stream
def cal_Entropy(imm, file_stream, file_size):
frequency = [0 for i in range(256)]
for i in file_stream:
for j in range(256):
if(ord(i) == j):
frequency[j] += 1
sum_entropy = 0
for i in range(256):
if(frequency[i] != 0):
sum_entropy += (float(frequency[i])/float(file_size)) * math.log(float(frequency[i])/float(file_size), 2)
return sum_entropy * (-1)
def record_Entropy(addr_BP, entropy, count):
with open("C:/Users/kimse/Desktop/record_entropy.txt",'a') as f:
data = str(count) + " -> BP_addr : "+str(hex(addr_BP))+" E : "+str(entropy)+'\n'
f.write(data)
f.close()원래는 start, end 값은 pe 헤더를 파싱 해서 초기화해야 하는데 gcc, 비주얼 스튜디오 등 다른 컴파일러로 컴파일하면 보호 기법과 최적화 옵션 등에 의해 base 값이 헤더랑 조금 다른 부분이 생겨서 그냥 하드 코딩을 진행했습니다.
(추후 이 부분을 수정하도록 하겠습니다.)
이제 이 소스코드를 C:\Program Files (x86)\Immunity Inc\Immunity Debugger\PyCommands에 넣고 명령어를 돌리도록 하겠습니다.
디버거 아래 명령창에 !(아까 저장한 파일 이름)을 입력하면 됩니다.
장정 4시간이 지나고 중간에 에러가 나서 전쟁 날 뻔했지만... 기록된 엔트로피 정보를 확인해 보도록 하겠습니다.
흠, 일단 시각화를 진행해 보도록 하겠습니다.
아래는 파일 내용을 파싱 해서 그래프로 그려주는 소스코드입니다.
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 1 18:12:34 2022
@author: kimse
"""
import matplotlib.pyplot as plt
def file_parser():
x_count = [0 for i in range(3434)]
y_E = [float(0) for i in range(3434)]
BP_addr = [0 for i in range(3434)]
index = 0
i=0
parsing_context = ''
with open("C:/Users/kimse/Desktop/record_entropy.txt",'r') as f:
while(True):
parsing_context = f.readline()
if(parsing_context == ''):
f.close()
break
index = parsing_context.find(' ')
x_count[i] = int(parsing_context[0:index])
index = parsing_context.find('E : ')
y_E[i] = float(parsing_context[index+4:(index+17)])
index = parsing_context.find('BP_addr : ')
BP_addr[i] = int(parsing_context[index+10:index+18],16)
i +=1
notDupl_BP, frequency_BP = delete_duplication(BP_addr)
grape_Entropy(x_count, y_E, BP_addr, notDupl_BP, frequency_BP)
def delete_duplication(BP_addr):
notDupl_BP = []
for i in BP_addr:
if i not in notDupl_BP:
notDupl_BP.append(i)
frequency_BP = [0 for i in notDupl_BP]
index = 0
for i in notDupl_BP:
for j in BP_addr:
if(i == j):
frequency_BP[index] += 1
index += 1
print(frequency_BP)
print(notDupl_BP)
return notDupl_BP, frequency_BP
def grape_Entropy(x_count, y_E, BP_addr, notDupl_BP, frequency_BP):
plt.plot(x_count, y_E)
plt.show()
plt.plot(notDupl_BP, frequency_BP)
plt.show()
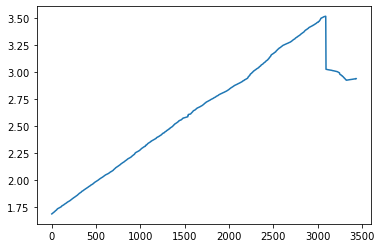
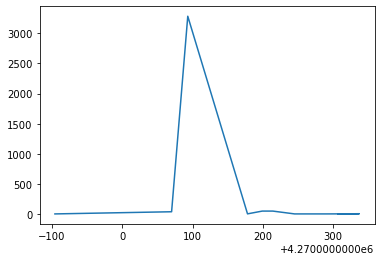
file_parser()첫 번째 그래프는 중단점을 만났을 때의 엔트로피 값의 변화를 측정한 그래프이며, 두 번째 그래프는 중단점을 설정해놓은 주소의 접근 카운트한 값을 시각화한 자료입니다.
runfile('C:/Users/kimse/Desktop/untitled0.py', wdir='C:/Users/kimse/Desktop')
[1, 37, 3284, 2, 48, 48, 1, 1, 1, 2, 4, 4, 1]
[4269904, 4270070, 4270093, 4270178, 4270199, 4270214, 4270245, 4270266, 4270291, 4270312, 4270335, 4270337, 4270307]따로 중단점 주소를 저장한 리스트의 중복을 제거한 값의 리스트와 접근 카운트 수 리스트를 출력해 보니 4270093(0x41280D) 번지에 가장 접근을 많이 했음을 알 수 있습니다.
3087 -> BP_addr : 0x41280dL E : 3.51941181314
3088 -> BP_addr : 0x41280dL E : 3.51925237134
3089 -> BP_addr : 0x41280dL E : 3.51871360336
3090 -> BP_addr : 0x41280dL E : 3.51865095797
3091 -> BP_addr : 0x41280dL E : 3.24787326933
3092 -> BP_addr : 0x41280dL E : 3.02834624661
3093 -> BP_addr : 0x41280dL E : 3.02818018194
3094 -> BP_addr : 0x41280dL E : 3.02795380003
3095 -> BP_addr : 0x41280dL E : 3.0278426709
3096 -> BP_addr : 0x41280dL E : 3.02774967238
3097 -> BP_addr : 0x41280dL E : 3.02744161046
3098 -> BP_addr : 0x41280dL E : 3.02726187221
기록된 엔트로피 변화량을 봐도 급격히 값이 줄어드는 부분은 4270093(0x41280D) 번지임을 알 수 있습니다.
upx 언패킹시 실제적으로 이동하는 OEP 주소는 0x4128d5이며 오차가 조금 있었으며, 아무래도 기록 중간에 프로그램의 크래시가 발생하면서 제대로 측정되지 못한 부분도 있다 보니 정확한 값을 확인하지 못한 듯합니다.
그래도 확실한 것은 내부의 코드 언패킹 과정(코드 압축 해제 및 iat 세팅 등)에서 엔트로피를 측정하여 언패킹 루틴 부분의 코드를 찾을 수 있다는 점입니다.
물론 엔트로피 측정 방식의 한계는 다음과 같습니다.
1. 실행 중에 가장 확실하게 측정하는 방법은 OP 코드 실행 단위로 측정하는 방법이 있으나, 굉장한 시스템 부하를 준다.
-> 그러므로 call, jmp와 같이 코드의 실행 분기가 바뀌는 지점을 중심으로 체크를 진행하면 효율적으로 분석이 가능하다.
-> 단, 윈도우에서 제공되는 DLL과 같은 녀석들은 체크되지 않도록 main 모듈의 주소 범위 내에서만 검색이 가능하도록 제한을 거는 것이 좋다.
(효율적인 측정이 가능하다는 것이지 빠르다는 말은 안 했다...)
2. 엔트로피의 변화 그래프의 변곡점이 2개 이상일 경우 OEP를 어떻게 특정해낼 것인가?
-> 개발자의 여러 트릭이 있을 수 있다.
-> 단순히 엔트로피를 속이기 위한 더미 코드의 동작일 수도 있고 실제 필요한 데이터가 내부에 나누어 저장되어 있을 가능성도 있다.
-> 물론 이것이 악성코드 패킹의 일부인지 아닌지는 해당 변곡점(의심 지점) 주변으로 조사할 필요가 있다.
3. 추가적인 문제
-> 위에서 언급한 것처럼 엔트로피 기반이기에 계산량이 많고 OEP를 잡지 못하는 경우도 많다.
-> 또한, 직접적인 실행이 필요하다는 점에서 익성 코드 시 샌드박스가 필수라 성능과 시간 면에서도 퍼포먼스가 떨어질 수밖에 없다.
-> 이를 해결하기 위해서는 가상 환경, 샌드박스, 리포팅 연구가 수반되어야 한다. 다만, 당장 답이 나올 것 같지는 않다.
제가 참고한 논문에서도 대부분 연산을 줄이고 효율적인 엔트로피 측정과 OEP 지점 검색에 집중되어 있었는데 괜히 언급된 것 같지 않습니다...
일단 오늘은 여기 끼자 작성하겠습니다.
다음에 기회가 되면 추가적으로 연구 내용을 올리도록 하겠습니다.
이상! ICMP였습니다. 감사합니다!!!
기술 및 자료 출처)
- 이영훈, 정만현,정현철,손태식, 문종섭 "엔트로피 값 변화 분석을 이용한 실행 압축 해제 방법 연구"
- 이원래, 김형중 "명령어 주소 엔트로피 값을 이용한 실행 압축 해제 방법 연구"
'보안 연구 > Reversing' 카테고리의 다른 글
| 악성코드 분석일지 - AgentTesla(진행 중) (0) | 2022.02.17 |
|---|---|
| 프로젝트 5일차 (0) | 2022.02.14 |
| 바이너리 언패킹(1) - 엔트로피 계산 (0) | 2022.01.28 |
| 프로젝트 4일차 (0) | 2022.01.15 |
| 프로젝트 3일차 (0) | 2022.01.15 |